Coupling and Cohesion: Fundamental Information Model
WIP
What is ‘Coupling and Cohesion’ and why you should care
The job of development
This is change. We change things. We sometimes build new things - but those new things facilitate change in the organization they are built in. But generally development should be viewed as a practice of recrafting how information flows through organizations. This could be another vague reference to conway’s law - but I feel also something more fundamental.
We model and define how information flows through graphs
Every time you model anything you have a graph with nodes and edges.
Right now there is me at a keyboard typing this - a node - and that is connected - by an edge - to you the reader debating about whether it is worth continuing reading this. But we can zoom in an discover that the edge is just an approximation and can be expanded into many more nodes and edges - eg computers, internet etc. So abstraction in this sense is a form of compression - a heuristic convenience to help us not have to think of everything. It also helps indicate to the consumer that all that detail is not considered relevant for the expressed meaning.
It is the job of development to change these networks. I think of this activity as information engineering (except that term is taken - much like when i wanted to invent a study of the logic (ology) of science and chose a very unfortunate name) - and it puts me at odds with many people as often the role of development is increasingly viewed as data entry experts in a language like javascript. Whilst data entry is partially true it is not sufficient to cover development.
The plan for this wall of text
I think the concepts of coupling and cohesion apply incredibly well to this network diagram - which means I also think they apply to information models and so everything we can model. If we can draw then it we can talk about coupling and cohesion. As a result these 2 concepts are versatile and powerful - because knowledge of games in one context will have analogues in others.
What I want to do here is get into this in some detail. By taking a target audience (developers) I want to show how a concept based upon coupling can be applied to increase cohesion and improve the health of a system in a systematic, repeatable and predictable way. I also want to show how hard this is to do in many different systems.

Then based upon this explore the idea of DeathStars again - from another thing I wrote about - and look for examples of these by zooming out and looking at larger structures in the information model. Here we can discuss software architecture and various strategies to eliminate death stars or - as will likely end up being more correct - choosing the deathstar that works best for you.
Then from here I want to keep zooming out to team structures and organizational patterns and how these relate to coupling, cohesion - and yes, death stars.
How to restate development in terms of information models?
The goal of development is to change a system to meet certain objectives - EG to change inside some constraints to maximize or more towards (or away) from some measurable thing. More of this, Less of that. When we take this view then we will have a model of current state and a model of future state. The job of development is to build and execute the decision graph that gets from one state to the next future state.
In some industries and problems this is far more obvious than others. When you are in manufacturing and are looking at how to run a plant that are a lot of very measurable and predictable things to look at and then model around. This is where ideas like lean manufacturing and theory of constraints (for manufacturing) came about. Here it comes down to accountancy, elimination of waste by understanding what inventory is.
TOC Crash Course
Theory of constraints contains many ideas, techniques and systems but in the end it all comes back to a simple observation.
- Any system that produces something consists of a set of sequential actions that converge upon the product. These sequences form converging chains.
- In a chain if it is put under tension there will be a weakest link.
- If we decide to strengthen the chain then doing work to do so on any point other than this will not add strength. This with will be waste.
- In organisations when we increase efficiency accross an org this is equivalent to doing so accros every link. Instead we should be investing all that effort into something focussed and better directed towards something of value.
- The key is identifying this weak link, this constraint and then designing the system around it. Then repeating this process.
Rope drum and buffer

On a walk different people walk at different paces. The front speeds off, the back lags. However the walk is only finished when the slowest finishes. if the slowest is at the back people wait - but then do not allow it to rest sufficiently whilst they get rest. The back rushes to catch up causing more need for rest. Its motion is not laminar, smooth and efficient. This kind of arrangement actually contributes to the slow being slower. What would actually help is taking load off the slowest, putting the slowest in the front and everyone taking rests with the slowest. Now the slowest can move at its maximum sustained pace and the walk operates vastly differently with the other fast parts taking as much work off and supporting the slowest. This is how a system that takes TOC into account feels. Everything working towards getting the slowest part to have an easier time.
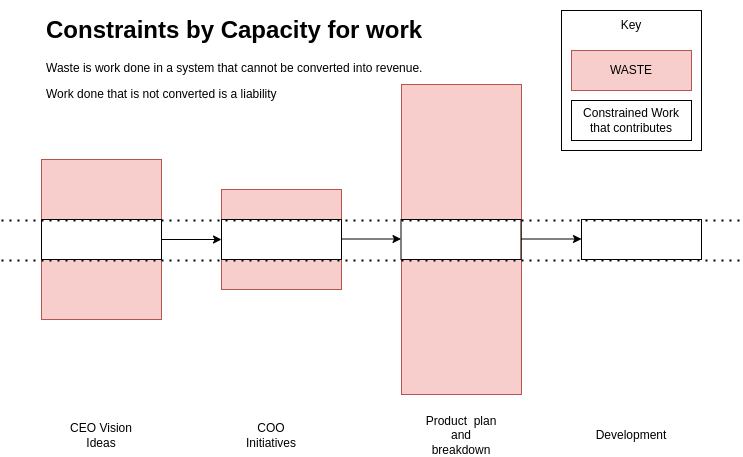
This image is a very typical situation for many organisations. They try to shove more work through the system than is possible. This is why organisations probalby waste 80% of their effort.
This kind of analysis is possible by understanding the coupling and then rearranging the parts of a system so that they work towards a coherent whole. When the system works in parts that optomise themselves at expense of the whole there are lots of seperate blobs coupled together. AFter TOC is applied it is a single cohesive system of parts coupled together and working together.
Not all systems behave the same way - kinds
However not all systems share the same properties as some are unpredictable. They have highly dispositional states and so exhibit complex behavior. When you perform the same activity twice we have learnt that we do not expect the same output in many systems.
Chaotic
Systems involving people or physical systems with more than 2 bodies (this can be viewed as constraints constraints - eg double pendulum connecting bars (edges) to rotating joints (nodes) and creating a chain of more than 2 nodes - a fixed point of attachment, a node hinge connecting one bar, and then a node that is free to rotate around the hinge at a length given by another bar) are highly sensitive to starting conditions and have feedback loops that lead to chaotic behaviors.
Examples of systems like this are anything involving a human in a feedback loop (ie a customer). In some systems (Eg a consultancy) inventory is not obvious (I have modelled it in the past as people who can be deployed as fee earners) - and the implications of inventory being human are enormous (not least because in consulting inventory (people) can be resold (deployed onto new clients)).
Sympathetic
It is interesting to also point out the opposite effect caused by perhaps unexpected coupling. A great example of this is wobbly bridges being caused by the bridge vibrations pushing people to all have their footsteps in sync that in turn feed backs into the bridge until a critical point where failure or injury could occur. This phenomena is due to coupling of apparently independent actors via the bridge. What you can see in the video is heads moving side to side in phase with one another. The fascinating part of this is that 150 people don’t cause that much of an effect but 164 have a dramatic effect.
There is another great Veritasium video on this phenomena for anyone who wants a bit of depth from someone far better at explaining depth and contextualizing. However a lot of ideas in this video have been borrowed in areas that we are discussing here as these phenomena are very important because they describe phase transitions - this concepts analogies can be applied to how to induce change in organizations when we look at the work of David Snowden.
So what?
It is worth noting that this video ends with exactly the problem that is being discussed here. How do we, when armed with an analysis of the parts, understand properties of the whole. What this piece of work is is a discussion of how we can start to break systems down into parts and understand properties of those parts based on the type of system they are. It is how cohesive these systems are and how the parts of them are coupled that is going to be of interest. Moreover it is how we are going to move parts around in a network to manipulate the ways in which we can talk about them
What this means is that applying concepts and ideas from one context without being aware of the kind of system is simply going to lead to unpredictability and not work as expected. We can see this all over development. If your company applies the same methodology to every project you are witnessing it - moreover you are probably aware of some places where it works better than others.
However this is why taking ideas from one area and looking for analogues in another is interesting and hopefully insightful as to how a system might be refactored. This is what happens in books like The Phoenix Project or Theory of Constraints. However the assumptions and conditions behind ideas need to be uncovered in order to test their validity by comparing it to the context they are about to be applied to. Eg the phoenix project is all about solving devops and support, not finding market fit for a new product. However the core formal reasoning process in there can be adapted as it was about modelling an information flow to find a bottleneck and uncover constraints.
The phenomena
- aka we fix one thing and something else breaks
 We spend most of our time changing existing systems and trying to figure out how systems work.
As such our ambition should be to build systems in ways that makes them easy to change - change also implies that we do not know what the system will need to do in a short period of time. As such we also need to be working in ways to learn and get to this change.
We spend most of our time changing existing systems and trying to figure out how systems work.
As such our ambition should be to build systems in ways that makes them easy to change - change also implies that we do not know what the system will need to do in a short period of time. As such we also need to be working in ways to learn and get to this change.
 Sometimes we have ‘happy little accidents’ but most often we have stuff that suddenly breaks unexpectedly. This is because when we change something and expect an effect there was something we didn’t know about in the system that we than say caused something else to happen. Our system is more complex than we thought. This complexity makes it exceptionally difficult to change systems - which is our entire job! so what can we do?
Sometimes we have ‘happy little accidents’ but most often we have stuff that suddenly breaks unexpectedly. This is because when we change something and expect an effect there was something we didn’t know about in the system that we than say caused something else to happen. Our system is more complex than we thought. This complexity makes it exceptionally difficult to change systems - which is our entire job! so what can we do?
- we can draw pretty boxes around things and lines between them to stave off the eldritch terrors.

Simple vs complex
Anything we can do to make our lives simpler here will pay off monumentally because systems size often exceeds our capacity for mental models. We need to be able to forget parts of a system and use heuristics and assumptions to work effectively. This requires predictability. Predictability with low cognitive effort requires simplicity.
Coupling and Cohesion are words that describe complexity in the sense of complect - to braid parts of a system together. Rich Hickey gave a great talk on simplicity.
‘The Agility of simplicity dominates all other forms of agility’
The more complected a system is then the more of a hairball it is. But also, the more parts effect other parts which makes it dramatically harder to reason about and be correct in our expectations.
Simplicity requires that separate parts of a system be as independent as possible. By not coupling these parts together we create firebreaks that limit the impact of change. This then allows us to compartmentalize and start to build heuristics - rules of thumb - that enable reasoning of larger parts of the system.
There is a lot of cargo-culting and kool-aid
However we also have to consider the cognitive cost of introducing these abstractions. A lot of software developers practice Don’t Repeat Yourself and a weird form of Single Responsibility Principle that cause a lot of harm. For instance the first 2 paragraphs in the SRP link contradict themselves. Is says Robert Martin made up the term and defined it in the second paragraph but only after proposing the common misunderstanding first (its a misunderstanding because it is insufficient on its own). The danger is taking heuristics like these and blindly applying them.
Create pretty diagrams / comic strip
It is very possible (and common) for 2 pieces of code to be almost identical but have different owners. When you apply ‘do not repeat yourself’ and extract them then not only have you invented work to do this (rather than do something that directly adds value to the customer), but you have also complected 2 parts of the system together by introducing the third shared piece of code. As a result, changing the common code for one will break the other because these 2 pieces have separate owners and so change in both will happen at different times for different reasons. Obviously getting the 2 parts to change concurrently and synchronously is vastly more complex than the parts doing so independently and therefor eventually sequentially. What is more, if this is extracted out into an independent package (to avoid this problem) then the package maintainer - as a result - has no real idea what the consumers are using it for. The goal for a package is to decouple from the consumers to allow them freedom - now changes to the package require a lot of communication and synchronization between consumers. Changes for one system will not be timed correctly for the other even if desired because different teams have different priorities - and if they do not then why split in the first place? Now there is a package with 2 versions in one place and 2 pieces of code running different versions because one has not yet (or doesn’t want to or cannot) update. Has this made things simpler? Was the intent to get into all this? Applying do not repeat yourself here automatically is not good - it is overzealous and increases complexity despite apparently increasing cohesion and lowering coupling. When the 2 pieces of code have different owners refactors like this introduce a new form of contract of change between both the teams and also between the teams and the shared code. This example is the most common and damaging misunderstanding I see applied again and again at all levels of development. It is disastrous yet completely prevalent. It took 14 years for someone to question me doing this and then another 2 for me to finally get why they were telling me this.
The cost of making the code ‘simpler’ is more complex deployment and the introduction of cross team concerns - usually to save 2-3 lines of ‘repeated’ code. The fix to the deployment here is to not take the external dependency, inline the code and get right back to the anti-pattern that was originally there. This happens but it should be said the heuristic is pretty good most of the time (provided the code has the same owner) - however remember the goal of encapsulation is to enable the movement of code into different services or places. Being self contained and not having external dependencies greatly aids this. This is where we get into the direction of coupling as well - but more on this later. The example above ends up badly because the direction is the wrong way around.
The common statement (low coupling, high cohesion) is insufficient as it is incoherent to the overly simplistic view people take of larger systems. We can do better!
What really matters? Predictability
Simply put, we cannot change a system if we do not know what will happen! To do so would be negligent.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/49493993/this-is-fine.0.jpg)
We want to really understand the predictability of systems. This allows us to know whether we have a system that we can test against reality. Moreover it allows us to say that when we do test it we also know what we expect to happen. In businesses we call this making money, in product it is knowing your customer, in code it is getting the bloody thing to firstly compile and secondly do what we want.
Information Model and Context
I have been finding recently that I think in ways that frustrate a lot of people. When trying to explain something and understand something (like the 2 concepts here) I understand them through their many different connections to other ideas. I will connect them with different ways of using them. By enumerating those different ways I think I am adding to either existing contexts or adding new contexts (or games).
The act of doing this reduces the cohesion of the original thing I was talking about because as you couple that idea to an increasing number of other ideas that seem to be coherent with one another it gets harder and harder for the victim to keep clean walls around the original idea. But this is a thing we grapple with every day - the concept of the ‘product’ a business sells is completely different in each different department of an organization. In ecom product for people managing client accounts is all about market, availability and margin whereas product for a site team is data to be shown on a site and getting it to edges quickly. Product for a warehouse is about unpacking, shelving, completing orders, packing and distribution - and less about the individual items. Nobody is more correct than anybody else - its just different but additive to a full understanding. Provided we keep the different conceptualizations separate (and cohesive) we can couple these different meanings together - and by exploiting this we have a functional cohesive company.
Exploiting Cynefin to build information and to deliberately identify unpredictability
The complaint I get is that my way of thinking and understanding has become too complicated. The ideas are too complex because they cannot be applied predictably because information overload.
Coupling and Cohesion are 2 concepts that work together to give us tools to describe the connections, globbyness and uniformity of information models. This matters because doing this well has a large impact on the predictability of systems.

When we are talking about predictability of systems in my brain we are in the realm of Cynefin and its analysis of complexity. In software most of our systems are complex adaptive systems as they interact with people - customers.
For instance, systems with extremely low cohesion and low coupling (eg a perfect gas) are also chaotic systems that can be exploited as they are also statistical systems because their parts are independent. Therefor if we can manipulate and reduce coupling and cohesion then we can convert at least parts of systems into states upon which we can use statistical tools.
An example of why this matters is the bridge from above. The bridge was designed so that the humans crossing it could be tret as chaotic independent bodies - with no coupling - whose forces on the bridge would largely cancel out. As a result the human part was chaotic but the bridge was complicated. The parameters of the bridge were very carefully chosen to create this state with the 2 cohesive parts being coupled spatially to combine into the behavior of a functional bridge. What was discovered was that the bridge human system was more complex as a temporal factor was involved do to the sideways forces of footsteps inducing resonance between and in both systems to turn into a positive feedback loop. IE There was an additional constraint on the horizontal frequency connecting the bridges horizontal resonant frequency with the frequency of human footsteps. This coupling was unknown and as such now forms a new constraint in engineering manuals. Its obviousness once known is often a remarkable feature of discovering constraints. By adding damping this temporal factor could be controlled. Future bridges could have a different horizontal resonant frequency which would allow a more static heuristic analysis of them.
Additionally, systems with badly understood coupling are going to be systems that when poked do unexpected things - a system that is partially or temporarily predictable is a complex system.
System with very high cohesion and well understood and mapped coupling tend towards simple from being complicated. By creating islands of cohesion it is possible to find islands of simplicity inside a complicated system.
This leads me to think in this sort of metaphor that moving from complex to complicated is the exercise of identifying the nature and kinds of coupling in a system. In code systems which is what is the main focus of myself a lot of complexity comes from difficulty of inspecting at compile time. Whereas some systems are very dispositional and feedback into themselves - this is I suspect very closely related to Heisenberg uncertainty - but in a system with a person if you interact with it in the same way twice it is unlikely to behave in the same say twice. This is because last interaction in some - perhaps metaphorical - way changed its starting state. These dispositional systems truly are complex - whereas some code systems are complex only because we did it badly.
The goal here is to use some tools to get into what does bad look like? how do we detect and find it? what tools do we have to play with it once we find it?
Cohesion
What is Cohesion?
Cohesion doesn’t seem to have a good example of a metric (entropy is possibly analogous - however that maybe more confusing!). Therefor I am going to have to get more figurative and illustrative. Systems that have low cohesion have uniformity. The canonical example in my mind would be a perfect gas upon which PV = nRT would apply to. It is a system which may have an effectively infinite number of parts because the parts are so homogenous, indecipherable and interchangeable that they are effectively one glob. As a result the glob of a system as a whole could be described as a cohesive lump if it had boundaries. As such a container around this could be said to have high cohesion. This then leads into the ancient question of ‘if you have a vase with nothing in it and take away the vase - where is the nothing?’ - anyway, I will leave you to ponder on that and its relation to the concept of self.


Water molecules in a glass of water have low cohesion whereas the hexagonal cells in a honeycomb have high cohesion. Whilst both plant cells and animal cells are on their own cohesive I would say collections of plant cells are more cohesive than collection of animal cells.
I also think that contrast is a great example of how complexity can interact with coupling and cohesion. A collection of plan cell looks less complex than the animal cells - it would seem reasonable to say behavior of the different would be more uniform as they look the same. In the animal cell example (stomach lining) there is more variety of structure and purpose - combining these different functions into the same collection makes the collection less cohesive - and perhaps less predictable as to its function per sample.
Cohesions curious relationship with complexity
One of the definitions of complexity when you get into Cynefin and playing tricks there is that a complex system is one where you do not know all the constraints. The evidence for this is one where you make a change expecting one thing and a different thing happens. This is a property of a dispositional system - and system involving people tend to be like this. A complex system where you cannot establish the constraints through analysis alone. When we see coupling below we will meet connascence, in that idea there are forms dynamic coupling that are only visible at run time. Therefor without the concept of connascence these systems would remain complex and unpredictable but by applying and using the language and games of connascence (such as mapping activities) it is possible for these to become complicated.
Ants marching in lines are more cohesive than a swarm of locusts. So we could try to say that by increasing the cohesiveness of something we are sucking the chaos, the entropy out of it. However it is possible to have a system that has high cohesion with a part that is chaotic - this is desirable and necessary in many cases (reality is chaotic). Eg a random number generator or the system that includes someone measuring the outside temperature.
Things with more cohesion have very different properties to things with very low cohesion. I believe this can end up being related to an idea of constraints and system complexity in Cynefin.
Coupling
There is a lot of discussion between high and low levels of coupling. However this has always felt vague to me. This all changed when I found Connascence as suddenly these vague ideas that were mapping more onto encapsulation and numbers of connections now had some meat.
Low Coupling != Good
The problem with the common idea of low coupling as basically being high coupling but you put something in a box and point to the box is that it is overly simplistic. In reality there is a balance between going overboard and producing Fizz Buzz enterprise architecture.
When you extract all these parts into something common across systems you are coupling those systems together. This in turn means are all of a sudden it is possible to break another teams work - so some activities that lower levels of coupling can introduce incredibly hard to detect problems. This is not good! There is a need for something more subtle!
Simplicity == good
Something less simplistic (Connascence)
When writing code there is a concept called Connascence. This is a powerful tool for analyzing code and refactoring. The purpose of it is to enable conversations around understanding how things are coupled together. This then helps to facilitate conversations around deliberately choosing what coupling should look like or identify situations where different forms are more or less desirable. I will write about connascence as it applies to code more in future posts, however here I want to draw attention to 2 particular components.
Components of Coupling
Type
The type of coupling (the name) which I will again come back to immediately below.
Distance
The distance between the 2 things that are coupled. The larger the distance the harder it is to know that the things are coupled. This is experienced as downstream systems failing unexpectedly upon change. Kent Beck gave a great example of 2 services being coupled because when one changed in a way that increased its network traffic some seemingly unrelated service in any logical sense started to fail - because they were both in a data center accessing the world via the same faulty switch. We can reduce the magnitude of this metric of coupling by bringing things that are coupled closer together. For instance a lot of refactors will take sets of code changes that would effect multiple files through a system and refactor the system so that those changes happen in the same folder or file. An example of this would be refactoring connascence of algorithm into connascence of name by taking 2 pieces of code in different parts of a system - one part encrypts and the other decrypts some data. We can refactor this by taking these 2 coupled sides and moving that into a common class which is then referred to by its name. If we then found that we had multiple ways of encrypting/serializing in different areas we could also use an extract interface refactor to convert their connascence of meaning into connascence of name. Considering connascence and distance leads to things that change together living together - and things that change at different times for different reasons naturally being allowed to drift apart. That deliberate action of pulling and pushing things apart leads to the other concept - cohesion, but more on that shortly. As an aside this is the power of javascript - because json and js are so closely related the need for serializing and deserializing into a type system does not exist which gives is a unique set of superpowers and downsides that are very exploitable in the current world. Typescript - in this conceptualization - sacrifices some of this closeness (lack of distance) away in an attempt to gain and exploit different types of coupling.
Degree
The number of things. When something is coupled to more things it is perhaps unsurprisingly more coupled. The effect of this is that changes to something - or the things it is coupled to can effect the whole network of connections. In this network the edges are types of coupling and their strength is almost their distance. The final part that determines how hard it is to understand the effect of changing something is the number of things a node is coupled to. The reason we like to play with the type of coupling is that by tactically choosing a less severe form of coupling we can use things like compilers to detect when we have broken the contract by which we have coupled. The more things that are coupled the less non zero the changes of some unknown of horrible type of coupling. By being explicitly about the number of things we are maintaining a map of what is coupled to what that we can navigate and manipulate. I will again come back to this when writing up some stuff about architecture, event sourcing, CQRS and event modelling (and storming).
-
- The breakdown and naming of the types along with the sequencing of them enables moves and direction when refactoring. Eg performing an extract method refactor to convert connascence of algorithm into connascence of name.
Coupling in non-code contexts
Different levels in systems (fold left)