Death Star Architecture
What is Death Star Architecture and why you should care

A death star has a core. Around the core there is stuff. A DDD crafted death star would fall apart like a higher dimensional chocolate orange. The Death Star on the other hand might have segments - but if it does they are all heavily cross linked to aid its structural integrity. A well designed estate at enterprise scale has no such cohesion baked into it. Its survival and adaptability depends upon this and is achieved through domain events. It has isolation, a well defined structure to each part and a well defined value delivered by each part. The Death Star doesn’t - it does on the other hand blow up moons. The point being just because it blows shit up doesn’t mean its efficient to work with. I mean an old guy with a stick strolled in and turned off the tractor beam without anyone noticing.

The job of an architect is to build a structure that allows decisions to be delayed as long as possible - Robert Martin
This enables large simple solutions to complex problems. However, feeling the pressure to know when to make decisions is hard.
Unlike with refactoring code (connaissance and groups that practice together help build shared consensus) refactoring large scale architecturally is still very much touchy feely about the when. Or maybe thats just my ignorance (link me up!).
Devops and ‘measure the key things’ are helping here. But still, it won’t help with the deathstar - the death star happens earlier and gets you before you get the data to pressure change.
How to build a Death Star
Odds are you have an almost functional one and have some rebels in your business frustrating you already. But generally taking the following simple steps will suffice.
- Take the cheaper faster option.
- Take the cheaper faster option.
- Goto 1.
That is reality. If you don’t do this you are probably dead or already an established corporate entity in which case I am merely recounting the first 5-10 years of your life. Unfortunately there are many traps you will fall into on the way - namely taking on big dependencies. The most common are things like IDE’s, build pipeline and - the real topic here - big and expensive database that encourages you to make bad decisions. None of these need to be taken - or at least have options.
The result
One BIG database at the core of your business
All these different processes hanging off it, dipping in and modifying state for other unconnected processes to do more work with. And no ‘but schemas’ is not adequate (but its barley better than nothing).
The Cost
- 1-2 emperors that know the system
- Evil sith lord(s) that act as hippo
- lots of underlings that will shoot themselves in the foot - or get asphyxiated through use of the force - when they get frustrated and then try and fail to modify the system.
Its a classic co-dependance on gatekeeper relationships that is caused by ever and probably non-linear increasing complexity of the single system.

-
Pace of business development and value add drops off a cliff. Rather than develop more stuff to add value to a proposition you start to look for clients to sell the existing stuff to. This is where the real death star gets built.
-
Technical debt bought to ship gets duplicated as more clients come on board. Finally the return on work to ship pays, but now the budgets are all about marketing and scaling out rather than consolidation.
-
At this point things are small and so it is easier to integrate into database rather than model problems because problems can be fixed simply by updating a record here and there. It feels efficient and powerful - This is the problem

Congratulations you own a DEATH STAR
It looks a bit like this:
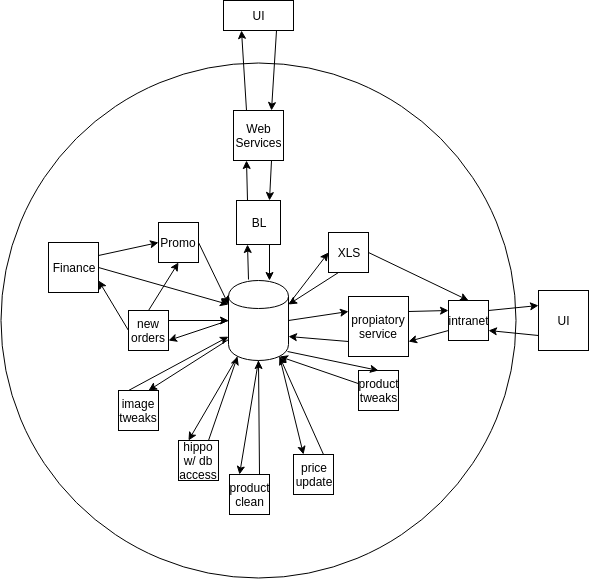
However that doesn’t look so bad. There are lots of separate stacks with not too many cross dependencies all talking with the database. If you squinted at a diagram involving bounded contexts you could argue this achieves that idea. And it does look similar - but then a cloud of sulfuric acid also looks a bit like fog.
The problem comes when we start to talk about value streams. Take an operationally important process (say a core business process such as getting products and prices into feeds) and map that value stream across these operations and you get something like this
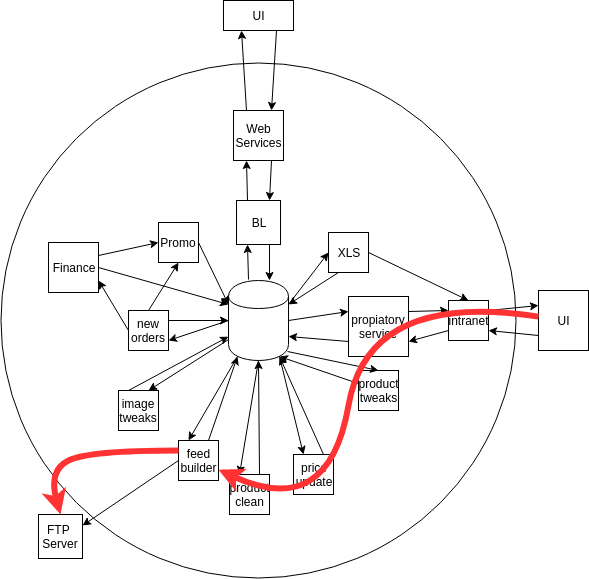
The problem is that every business process will look something like this and will overlap. Experts in one value stream / domain will potentially have no idea about the existence of others. But they will know this and so will be paralyzed by fear.
The Deathstar is fully operational. Its a huge frickin lazer beam, congrats. The problem is that if Vader ever remembers he asked for a ballpit to go with his evil egg you are going to need help - you have no chance.
Now the follow is true:
- Because nobody can change anything without breaking something you decide you have a quality problem - the existing stuff works and so survivor bias makes everyone point to the new work as being the problem and Hero Complex means the gatekeepers are essential.
- Gate keepers become the Heros and this becomes a cultural target. People subconsciously copy people that seem to have more social status.
- To fix ‘sloppy development’ development slows down, some heavy handed ‘agile’ implementation focus on Process, Documentation and Planning. (too subtle?)
- Lots of small problem solving per department ie local optimizations rather then whole company result in fragility.
- The estate is now a mess of braided knots with value streams spread across multiple solutions. This entire approach complects the whole system. This is the nature of a death star.
- Things like Branching become normal, doing CI on branches other than master (yet only having one db instance …).
- Just because dev stalled doesn’t mean the business did! it is literally impossible to meet the current businesses needs as development is now several months behind.
- Confidence in development drops, other departments solve their own problems. Nobody stops to think that this is crazy - its so normal. At this point there is no unified movement, its noise and conflict. Sure the road map is followed but rather than a crystal lattice you get an ants nest.
Getting rid of feature branches induces some serious cognitive dissonance. Maybe for another time …
So Death Stars are bad .. Now what
If you dont know anything about Domain Driven Design then that is probably a good place to start.
What would a non-deathstar-enterprise-scale-mess look like?
- Think in terms of value streams: map processes from the perspective of how they deliver value to the customer using something like Event Storming.
- Use these value streams to separate your domain into bounded contexts.
- Build a fleet of mini death stars
But why is this different?
- Most importantly the Single Responsibility Principle
- These contexts use completely isolated datastores.
- You can blow up all your enemies at once
- Your DBA’s probably are grateful but a little bored now
When code, modules, services, databases or whatever deployment units are being discussed are broken down with these kinds of considerations and the above approach then due to the isolation and singularity of purpose (that will be mapped end to end onto what the company actually does) you end up in a position more like this.
So Death Star bad, what does good look like and how to get there?
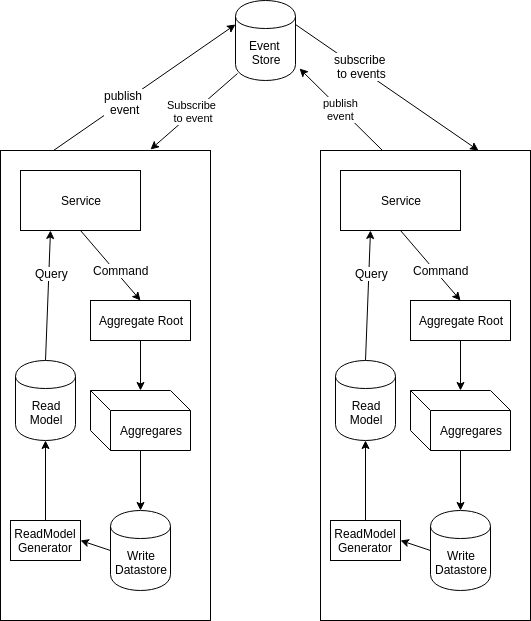
But what wait:
- How did CQRS get in there?
- Now an event store is just going to create another deathstar.
So CQRS: DDD is expensive (in the short term - i’d argue long term its far more effective), you would normally only employ it for core domain. Thats the bits that really add value to the customer - but thats what is under discussion here. If you have bounded contexts then you have domain events. You should use event sourcing at this point whether or not each bounded context is event sourced or not. The deathstar above didn’t - it just spewed side effects across the single integration point of all the separate domains. The entire point (here) of separating these bounded contexts is that using the same database across them is not a default assumption. Instead the choice of datastore should depend on the types of read and query.
In regard to deathstar the second. Yes, absolutely, hence all the articles over the years about enterprise service bus being an anti pattern, or people getting upset with api gateways and orchestration gateways. They hide logic and gradually incorporate more and more logic inside themselves - they are the opposite of databases and so have all the same problems. RabbitMQ (and probably Kafka - again someone please correct me :D) have the same problem with complex topic and exchange setups. Its a question of where the logic resides and the ability to do CD over it in a way that enables high confidence and cadence of releases.
However, what was never suggested was only one event source being appropriate or desirable.
Finally … Whats the worst that could happen right?